Directed Diffusion
Directed Diffusion est un protocole de propagation de données, permettant d'utiliser plusieurs chemins pour le routage d'information. Le puits diffuse un intérêt sous forme de requête, afin d'interroger le réseau sur une donnée particulière. Il se base sur le modèle publish/subscribe. DD repose sur quatre éléments : nomination des données, propagation des intérêts et établissement des gradients, propagation des données et renforcement des chemins.
La nomination de données
L'adressage dans DD utilise un schéma attribut-valeur afin de décrire les intérêts et les rapports de données.
Par exemple, dans une application de protection de forêts, une requête peut être effectuée sous cette forme :
Type = GetTemperature
Zone = [100, 100, 120, 120]
Interval = 10 ms
Durartion = 1 mn
Une réponse d'un capteur pourra être formulée ainsi :
Type = GetTemperature
Location = (110, 115)
Temperature = 32
Timestamp = 11:32:10
Propagation des intérêts et établissement des gradients
Lorsqu'un puits requiert une donnée du réseau, il propage un intérêt, contenant sa description ainsi que le débit d'information désiré. Initialement, le puits spécifie un grand intervalle, dans un but d'exploration. Cela permet d'établir les gradients et de découvrir d'éventuelles sources, sans pour autant encombrer le réseau.
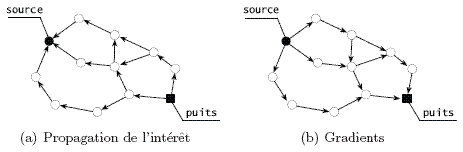
Afin de propager l'inéerêt, DD emploie l'inondation globale du réseau. Chaque noeud maintient localement un cache d'intérêt contenant les informations suivantes :
-
La description de l'intérêt, en utilisant le schéma de nomination.
-
Un ensemble de gradients.
Un gradient est un vecteur représentant l'intérêt. Il est caractérisé par une direction et une amplitude : la direction est modélisée par le voisin émetteur de l'intérêt, et l'amplitude est représentée par le débit de données. En plus, chaque entrée contient un champ limitant la durée de validité du gradient.
Lorsqu'un noeud reçoit un intérêt, il parcourt son cache :
-
Si le cache ne contient aucune entrée relative à l'intérêt reçu, une nouvelle entrée est créée avec un gradient vers le voisin émetteur.
-
Dans le cas contraire, le noeud recherche un gradient vers le voisin émetteur, et met à jour en conséquence l'entrée en question.
Après le traitement du cache, le noeud relaie l'intérêt vers ses voisins. La méthode la plus simple est d'utiliser l'inondation.
Propagation des données
Lorsque l'intérêt atteint les sources ciblées, les capteurs commencent la récolte d'information. Pour un intérêt donné, un capteur calcule le débit le plus élevé et prélève les données en conséquence. En consultant les gradients relatifs à l'intérêt, le noeud détermine les prochains sauts vers les puits (chacun avec son propre débit).
Lorsqu'un noeud reçoit une donnée, il recherche un intérêt équivalent dans son cache. Si aucune entrée n'est trouvée, le paquet est supprimé. Dans le cas contraire, en consultant la liste des gradients, le noeud relaie la donnée vers ses voisins, suivant le débit de chacun d'eux.
Avant de relayer une donnée à ses voisins, un noeud utilise son cache de données. Ce cache enregistre les données récemment émises par les voisins. Cela évite la création de boucles, en supprimant les données déjà rencontrées.
Renforcement des chemins
Lorsque le puits reçoit les premières données, il renforce le chemin vers le voisin émetteur, en augmentant le débit de captage. Cela permet de clôturer la phase d'exploration, et d'entamer la phase de récolte d'information. Le renforcement ne doit pas s'arrêter au niveau des voisins du puits, mais doit se propager éventuellement jusqu'aux sources. Pour ce faire, lorsqu'un noeud reçoit un message de renforcement, il consulte son cache d'intérêt. Si le débit spécifié dans le message est plus grand que tous les autres débits des gradients présents, le noeud doit renforcer un de ses voisins. Le voisin est choisi en utilisant le cache de données.
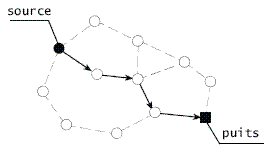
Dans le cas de panne d'un lien (perte de paquet, débit réduit, etc.) le puits peut envoyer un renforcement négatif sur le chemin en panne en spécifiant le débit de base (exploratoire), et en procédant à un renforcement positif d'un chemin alternatif.
")