Protocole CPEQ
En plus de tous les mécanismes de tolérance aux pannes qu'implémente PEQ, la variante CPEQ (Cluster-based PEQ) ajoute un module de clustering pour offrir une meilleure gestion de routage. En effet, les nSuds ayant le plus d'énergie résiduelle sont sélectionnés comme nSuds agrégateurs (appelés aussi cluster head ou hub). Un nSud agrégateur établit son cluster, et les nSuds appartenant à ce dernier envoient leurs données à l'agrégateur qui effectue d'éventuel traitement sur les données brutes puis les achemine vers le collecteur. Chaque nSud du réseau peut devenir agrégateur pendant une certaine période de temps selon son niveau de batterie. Le but principal de CPEQ est de distribuer d'une manière uniforme la dissipation d'énergie entre les nSuds, et de réduire la latence et le trafic de données dans le réseau. Le protocole CPEQ est réalisé en cinq étapes
Cette phase est basée sur l'algorithme PEQ ; où chaque nSud commence par un mécanisme d'inondation (diffusion) pour configurer tout le réseau et connaître par la suite le nombre de sauts nécessaires pour atteindre le collecteur. En outre, CPEQ introduit un champ additionnel contenant le pourcentage des nSuds qui deviendront agrégateurs ;
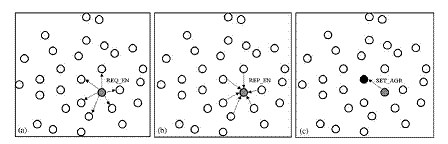
C'est la phase d'élection des clusters-heads (appelés ici agrégateurs). Après la configuration initiale, chaque nSud peut devenir agrégateur avec un pourcentage donné. En effet, chaque nSud génère un nombre aléatoire entre 0 et 1. Si ce nombre est inférieur à une probabilité p (probabilité pour devenir agrégateur), le nSud demande à tous ses voisins immédiats leur niveau de batterie en envoyant un paquet REQ_EN (Request Energy). Chaque voisin répond par un message REP_EN (Reply Energy) contenant son ID et la quantité d'énergie. Le nSud choisit le voisin ayant le maximum d'énergie et diffuse un SET_AGR (Set Aggregator) pour informer tous les nSuds du nouvel agrégateur. Les trois étapes de cette phase sont illustrées dans la figure suivante ;
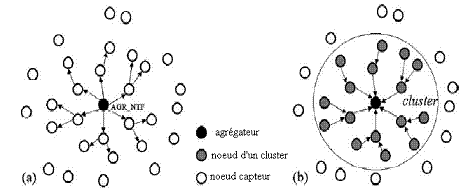
Cette phase divise le réseau en un ensemble de clusters. Le nouveau nSud agrégateur sélectionné doit avertir ses voisins de son rôle d'agrégation. De cette manière chaque agrégateur construit son cluster de nSuds. La configuration de clusters est réalisée à l'aide de messages AGR_NTF (Aggregator Notification) avec un champ TTL pour limiter la propagation du paquet sur les nSuds se trouvant à une distance inférieure ou égale au TTL. Chaque fois qu'un nSud reçoit ce message, il enregistre l'ID du nSud émetteur dans sa table de routage pour déterminer le chemin vers l'agrégateur. Si un nSud reçoit plusieurs messages AGR_NTF ; il choisit l'agrégateur avec le moindre nombre de sauts. La figure suivante illustre la configuration de clusters avec un TTL=2 ;
L'algorithme de routage des données est le même implémenté dans le protocole PEQ. Chaque nSud utilise sa table de routage pour envoyer la donnée vers son agrégateur. Dans CPEQ l'agrégateur peut être considéré comme un nSud puits. Le mécanisme de recouvrement de chemin est aussi hérité du protocole PEQ;
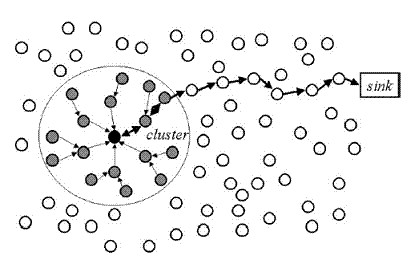
Après réception des données depuis les nSuds capteurs de son cluster, l'agrégateur doit acheminer ces données au collecteur. CPEQ utilise une communication multi sauts entre l'agrégateur et le collecteur tel que montre la figure suivant.
")